
A.K.A. 如何让 2000 元的机械硬盘跑得比 3000 元的固态硬盘还快(
背景
由中科大 Linux 用户协会维护的中科大开源软件镜像站是中国大陆高校访问量最大、收录最全的开源软件镜像之一。 在 2024 年 5 月至 6 月期间,我们的镜像站服务的流量大约是每天 36 TiB,主要分为以下两大类:
- HTTP/HTTPS 流量 19 TiB,请求量 1700 万
- Rsync 流量 10.3 TiB,请求量 2.18 万(如果算上一个异常的客户端,那么总数是 14.78 万)
多年以来,随着现有镜像仓库容量的增加和新镜像仓库的加入,我们的服务器硬盘容量已经十分紧张了。目前1提供镜像服务的两台服务器的磁盘容量都已经接近极限了:
- 主(HTTP)服务器采用 XFS 文件系统,在 2023 年 12 月 18 日达到了 63.3 TiB(总容量 66.0 TiB,使用率 96%);
- 副(Rsync)服务器采用 ZFS 文件系统,在 2023 年 11 月 21 日达到了 42.4 TiB(总容量 43.2 TiB,使用率 98%)。
两台服务器的配置分别如下:
- HTTP 服务器
-
- 2020 年秋季搭建
- 第二代至强可扩展处理器(Cascade Lake)和 256 GB DDR4 内存
- 12 块 10 TB HDD + 一块 2 TB SSD
- 在硬件 RAID 上使用 LVM 和 XFS
- 由于 XFS(截至本次重建时)不支持压缩,因此为了应对其他分区的潜在的扩容需求,我们在 LVM VG 层面保留了 free PE
- Rsync 服务器
-
- 2016 年底搭建
- 至强 E5 v4 处理器(Broadwell)和 256 GB DDR4 内存
- 12 块 6 TB HDD 和一些小容量 SSD 用来装系统和当缓存
- 组建了 ZFS RAID-Z3 阵列,分为 8 块数据盘 + 3 块校验盘,最后一块留作热备
- 全默认参数(仅修改了
zfs_arc_max)
这两台服务器的磁盘负载非常高,日常维持在 90% 以上,以至于即使从科大校园网内下载镜像,速度也很难达到 50 MB/s。 显然对于镜像站这种专用于存储用途的机器来说,这样的性能表现是不尽人意的。
ZFS
ZFS 以“单机存储的终极解决方案”著称。 它集 RAID、逻辑卷管理和文件系统于一体,具有包括快照、克隆、发送/接收等高级功能。 ZFS 内的所有数据都有校验,可以在硬盘出现比特翻转等极端情况下尽可能确保文件系统的完整性。 对于专用于存储的服务器来说,ZFS 看起来是个可以“开箱即用”的解决方案,但当你看到它有如此多的可调节参数之后,你马上就不会这么想了。
作为前期学习和实验,我在自己的工作站上增加了一批额外的硬盘并把它们组成了两个 ZFS pool,然后注册了一些 PT 站开始刷流来制造一些磁盘负载以便学习研究。
在 PT 站的刷流成果十分可观:这个单机的 seed box 在两年半间产生了 1.20 PiB 的上传量。
这两年刷 PT 站刷下来,我总结出来几个重要的 ZFS 学习资料来源:
- UToronto 的 Chris Siebenmann 的博客:https://utcc.utoronto.ca/~cks/space/blog/
- OpenZFS 的官方文档:https://openzfs.github.io/openzfs-docs/
- 我自己攒出的一篇博客:Understanding ZFS block sizes
- 以及这篇博客底部列出的参考文献
经过多年的 ZFS 学习,我意识到镜像站服务器上的配置其实有很大的优化空间,方法就是 all-in ZFS 并正确地调节一些参数。
镜像站
在开工重建 ZFS pool 之前,我们需要正确地理解和分析镜像站的负载类型。简而言之,镜像站的特点是:
- 提供文件下载服务
-
也(被迫)提供“家庭宽带上下行流量平衡服务”(责任全在 PCDN 方)
- 读多写少,且大部分读取都是全文件顺序读取
- 能够容忍少量的数据丢失,毕竟镜像内容可以轻易地从上游重新同步回来
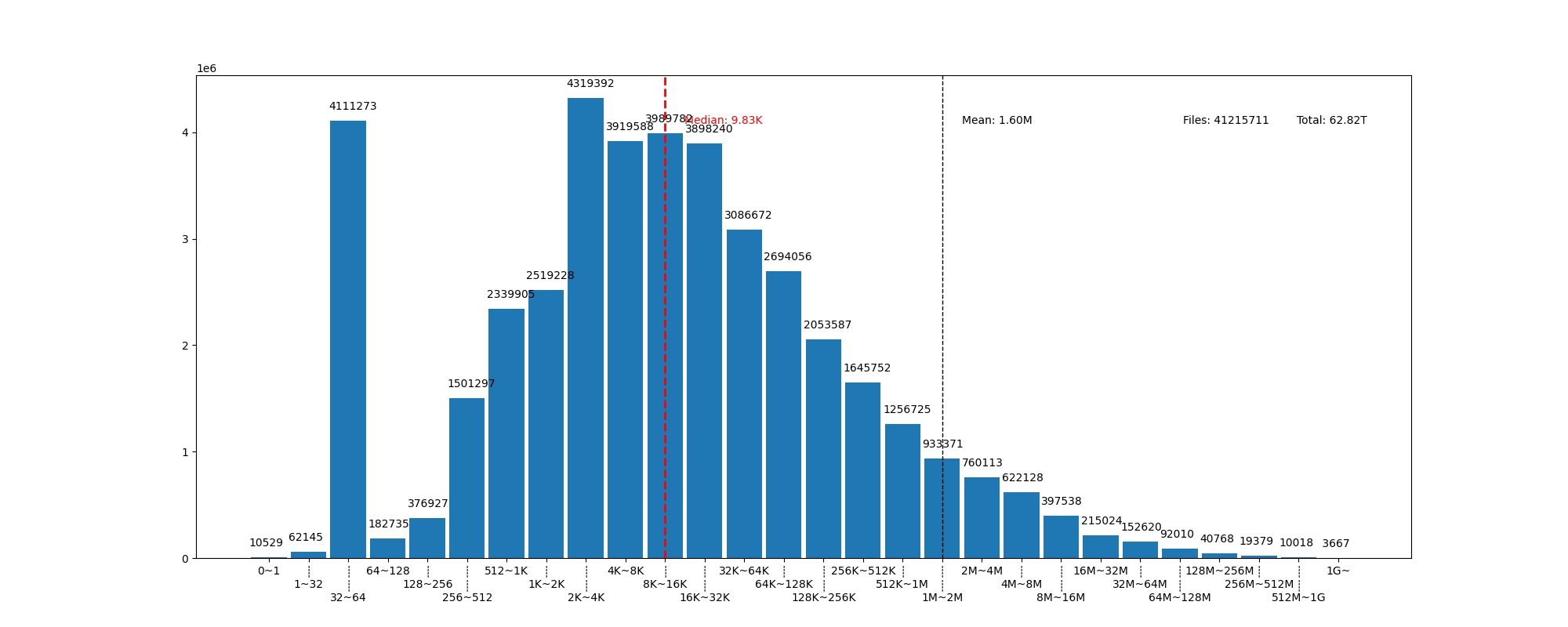
基于以上思考,我们分析了镜像站上存储的内容。从上图中可以看出,镜像站上总文件数超过 4000 万,其中一半的文件大小不到 10 KiB,并且 90% 的文件大小不到 1 MiB。 尽管如此,所有文件的平均大小仍然达到了 1.6 MiB。
重建 Rsync 服务器
Rsync 服务器的流量较少,但磁盘使用率较为极端,加上我们认定 Rsync 服务的重要性较低,因此在今年 6 月,我们先动手重建了这台服务器。 我们制定了如下的重建计划:
- 首先,考虑到镜像站上一半的文件都不到 10 KiB(注意我们的磁盘的物理扇区大小是 4 KiB),RAID-Z3 的开销过高,因此我们决定将其重建为 RAID-Z2 并且拆成两组 vdev。这样做还有一个额外的好处,即期望情况下我们还可以在这个 ZFS pool 中获得两倍的 IOPS,毕竟文件的每个“块”只存储在一个 vdev 上。
-
然后我们仔细研究了如何为镜像站场景调优 ZFS dataset 参数:
recordsize=1M:尽可能优化顺序读写性能,同时减少碎片化。-
compression=zstd:开点压缩来试试能节约多少磁盘空间。-
OpenZFS 2.2 开始将 early-abort 机制引入了 Zstd 压缩算法(Zstd-3 以上的等级)。该机制会首先尝试使用 LZ4 和 Zstd-1 来压缩数据以便评估数据的可压缩性,如果数据不可压缩(熵太大),则不再尝试用设定的 Zstd 等级压缩,而是直接原样写入磁盘上,避免在不可压缩的数据上浪费 CPU。
我们已知镜像站上的大部分内容都是已经压缩过的,因此 early-abort 算是给我们兜了个底,让我们可以放心地开 Zstd。
-
xattr=off:镜像站上的文件不需要扩展属性。atime=off:镜像站上的文件不需要记录,也不需要更新 atime,可以省掉不少写入。setuid=off、exec=off、devices=off也是我们不需要的挂载选项(也是一个更安全的做法)。secondarycache=metadata让 L2ARC 仅缓存 ZFS 内部的元数据。这是因为 Rsync 服务器上的文件访问模式更加均匀,而不像面向终端用户的 HTTP 服务器上冷热分明,因此仅缓存元数据可以节约 SSD 寿命。
-
以及一些可能有潜在(但我们认为我们可以容忍的)风险的选项:
sync=disabled:禁用同步写入语义(open(O_SYNC)、sync()和fsync()等)以让 ZFS 能够充分发挥写缓冲区的意义,如降低碎片率等。redundant_metadata=some:(OpenZFS 2.2)减少元数据的冗余度来获得更好的写入性能。
我们认为这两个选项符合我们对镜像站仓库内容的数据安全和完整性需求的理解,它们在其他场景下不一定“安全”。
-
对于 ZFS 模块层面的参数,光是 290+ 的数量就已经很劝退了。 此处感谢 Debian ZFS 维护者兼北京外国语大学镜像站管理员 @happyaron 的帮助,我们快速找出了十几个常用的参数进行针对性调节。
# 设置 ARC 大小范围为 160-200 GiB,并为操作系统保留 16 GiB 空闲 options zfs zfs_arc_max=214748364800 options zfs zfs_arc_min=171798691840 options zfs zfs_arc_sys_free=17179869184 # 设置元数据对用户数据优先级的权重为 20x (OpenZFS 2.2+) options zfs zfs_arc_meta_balance=2000 # 允许 dnode 占用至多 80% 的 ARC 容量 options zfs zfs_arc_dnode_limit_percent=80 # 以下几行参见 man page 中的 "ZFS I/O Scheduler" 一节 options zfs zfs_vdev_async_read_max_active=8 options zfs zfs_vdev_async_read_min_active=2 options zfs zfs_vdev_scrub_max_active=5 options zfs zfs_vdev_max_active=20000 # 避免因内存压力降低 ARC 读写速度 options zfs zfs_arc_lotsfree_percent=0 # L2ARC 参数 options zfs l2arc_headroom=8 options zfs l2arc_write_max=67108864 options zfs l2arc_noprefetch=0另外还有
zfs_dmu_offset_next_sync,但由于它从 OpenZFS 2.1.5 开始已经默认启用了,因此我们将其从本列表中略去。
将 Rsync 服务暂时转移到由 HTTP 服务器兼任之后,我们 destroy 了原有的 ZFS pool 并重新组建了一个新的 pool,然后再从外面(上游或 TUNA、BFSU 等友校镜像站)把原有的仓库同步回来。 令我们感到惊讶的是,把总共近 40 TiB 的仓库同步回来只花了 3 天,比我们预想的要快得多。 其他的一些数据看起来也令人振奋:
-
ZFS 压缩率:39.5T / 37.1T (1.07x)
需要特别指出的是,ZFS 只显示压缩率小数点后两位,所以更高的精度,需要通过原始数据自己计算:
zfs list -po name,logicalused,used我们更精确的压缩率是 1 + 6.57%,即压掉了 2.67 TB(2.43 TiB),约等于 9 份微信数据(不是
-
最关键的是更合理的 I/O 负载:

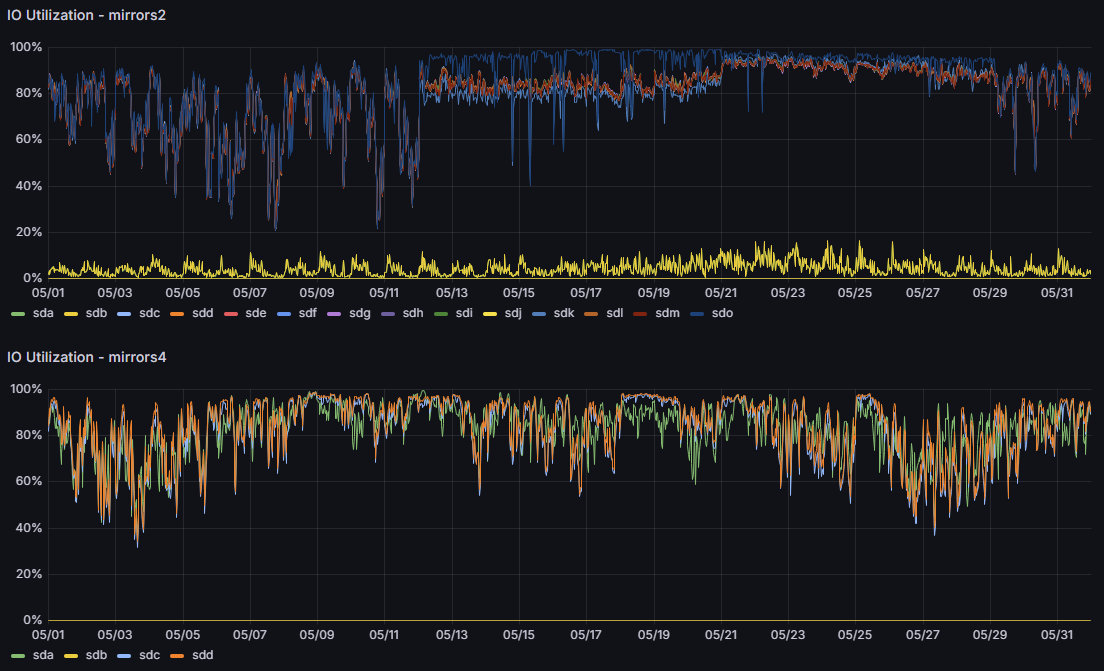
mirrors2 机器在重建前后的 I/O 负载
{kind=link}
可以看出,经过几天的预热之后,I/O 负载维持在了 20% 左右,而在重建之前一直维持在 90% 以上。
重建 HTTP 服务器
我们的 HTTP 服务器是在 2020 年秋季搭建的,并且当时也有一些不同的背景。 申请这台服务器正是因为 Rsync 服务器容量过满且性能不佳,加上当时社团内也没有熟悉 ZFS 的同学,我们对 ZFS 的印象很差,所以我们决定完全避开 ZFS,使用硬件 RAID、LVM 和 XFS,其中使用 LVM 的原因是 RAID 卡不支持跨两个控制器组 RAID。 对于“内存做缓存”这部分,我们决定直接使用内核的 page cache;而对于 SSD 缓存,我们则率先吃了 LVMcache 的螃蟹。
然而这些过于“新鲜”的技术并没有带来比(现在的 ZFS)更好的体验:
- XFS 无法缩小,因此我们不得不在 LVM VG 层面保留了 free PE。同时我们也不能把 XFS 文件系统用满,因此这里就有了两层无法利用的空闲空间。
- 我们最初分配了 1.5 TB 的 SSD 缓存,但 LVMcache 又建议我们不要超过 100 万个 chunk,我们当时也没有足够的精力和知识水平去研究这个建议背后的技术细节,因此我们最终只分配了 1 TiB(1 MiB chunk size * 1 Mi chunks)的 SSD 缓存。
- SSD 缓存策略不可调,多年以后我们翻了 kernel 源码才发现它是一个 64 级的 LRU。
- 配好 cache 之后 GRUB 立刻挂了(难绷),我们调查发现原因是 GRUB 有一套自己的解析 LVM metadata 的代码,它并没有正确处理(或者说根本没处理)VG 中有 cache volume 的情况,我们不得不自己 patch 了 GRUB 才能正常开机。
- 由于我们对 LVMcache 的 chunk 不够了解,我们的 SSD 在不到 2 年的时间里就严重超过了标称的写入寿命,我们被迫申请换新。
在 SSD 换新之后,即使我们认为我们对 LVMcache 做出了稍微合理一点的调参,坚持忽略警告采用 128 KiB 的 chunk size 和 800 万个 chunk 之后,它的性能(命中率)也并不可观:
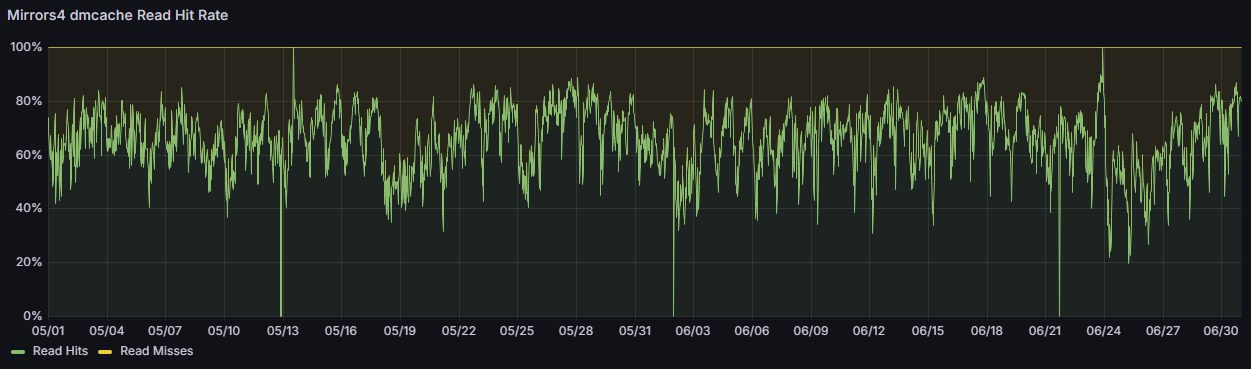
这些年来我们已经踩够了 LVMcache 的坑了,加上 Rsync 服务器重建的巨大成功,我们重新开始相信 ZFS 是天下第一的存储方案了。 所以一个月之后,我们又制定了一个相似的重建计划准备重建 HTTP 服务器,但是有一些微小的差别:
- 我们的 Rsync 服务器采用原生的 Debian kernel +
zfs-dkms,但根据我们使用 PVE 的经验,我们准备在 HTTP 服务器上直接用6.8.8-3-pvekernel,它打包了zfs.ko,这样我们就不用在 DKMS 上浪费时间了。 - 由于磁盘数目相同(12 块),我们也采用了两个 6 盘 RAID-Z2 vdev 的组合。
- 考虑到这台服务器直接向用户提供 HTTP 服务,磁盘的访问模式会比 Rsync 服务器更加冷热分明,因此我们保持了
secondarycache=all的设置(采用默认值,不动)。 - 这台新服务器的 CPU 更新更好,因此我们把压缩等级提高到了
zstd-8来试试能否获得更好的压缩比。
- 考虑到这台服务器直接向用户提供 HTTP 服务,磁盘的访问模式会比 Rsync 服务器更加冷热分明,因此我们保持了
- 我们在 Rsync 服务器上已经有了一个完整的、经过 ZFS 优化过的仓库,因此我们可以直接用
zfs send -Lcp把数据倒过来。我们最终只花了 36 小时就把超过 50 TiB 的数据都倒回来了。 - 由于两台服务器上存储的镜像仓库有所不同,HTTP 服务器上的压缩比略低一些,为 1 + 3.93%(压掉了 2.42 TB / 2.20 TiB)。
我们把两台服务器的 I/O 负载放在一张图里对比:
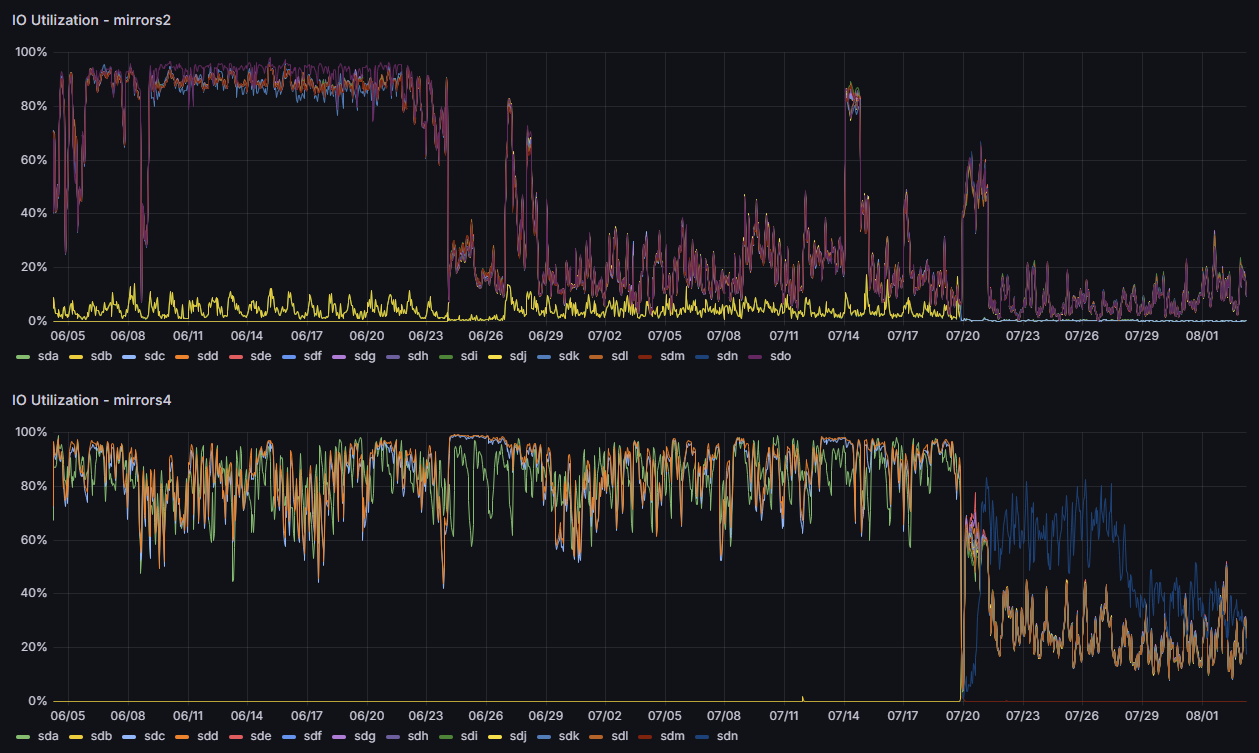
上图左半部分为重建前的情况,中间部分为仅重建了 Rsync 服务器的情况,右半部分为两台服务器都重建完毕后的情况。
ZFS ARC 的命中率也十分可观:

稳定下来之后,两台服务器的 I/O 负载还更低了:

杂项
ZFS 透明压缩
我们并没有想到这么多仓库的压缩率都还不错:
| NAME | LUSED | USED | RATIO |
|---|---|---|---|
| pool0/repo/crates.io-index | 2.19G | 1.65G | 3.01x |
| pool0/repo/elpa | 3.35G | 2.32G | 1.67x |
| pool0/repo/rfc | 4.37G | 3.01G | 1.56x |
| pool0/repo/debian-cdimage | 1.58T | 1.04T | 1.54x |
| pool0/repo/tldp | 4.89G | 3.78G | 1.48x |
| pool0/repo/loongnix | 438G | 332G | 1.34x |
| pool0/repo/rosdistro | 32.2M | 26.6M | 1.31x |
有些数字看着不太对劲(比如第一个),我们认为是这个问题造成的: openzfs/zfs#7639
如果我们按照压缩量排序,结果如下:
| NAME | LUSED | USED | DIFF |
|---|---|---|---|
| pool0/repo | 58.3T | 56.1T | 2.2T |
| pool0/repo/debian-cdimage | 1.6T | 1.0T | 549.6G |
| pool0/repo/opensuse | 2.5T | 2.3T | 279.7G |
| pool0/repo/turnkeylinux | 1.2T | 1.0T | 155.2G |
| pool0/repo/loongnix | 438.2G | 331.9G | 106.3G |
| pool0/repo/alpine | 3.0T | 2.9T | 103.9G |
| pool0/repo/openwrt | 1.8T | 1.7T | 70.0G |
debian-cdimage 一个仓库就占了总压缩量的 1/4。
Grafana for ZFS I/O
重建后,我们也修了一个显示 ZFS I/O 的 Grafana 面板。
因为 ZFS 的 I/O 统计数据是通过 /proc/spl/kstat/zfs/$POOL/objset-$OBJSETID_HEX 获取的,并且是分“object set”(即 dataset)累计统计的,所以我们需要先对每个 dataset 的数据做差分,再按 pool 加起来。
也就是说,一个 InfluxQL subquery 是跑不掉的。
SELECT
non_negative_derivative(sum("reads"), 1s) AS "read",
non_negative_derivative(sum("writes"), 1s) AS "write"
FROM (
SELECT
first("reads") AS "reads",
first("writes") AS "writes"
FROM "zfs_pool"
WHERE ("host" = 'taokystrong' AND "pool" = 'pool0') AND $timeFilter
GROUP BY time($interval), "host"::tag, "pool"::tag, "dataset"::tag fill(null)
)
WHERE $timeFilter
GROUP BY time($interval), "pool"::tag fill(linear)
由于 subquery 的存在,这个 query 确实有点慢,但我们也没啥能优化的。
如果要显示读写速率的话,直接把内层查询的 reads 和 writes 换成 nread 和 nwritten 就行了。
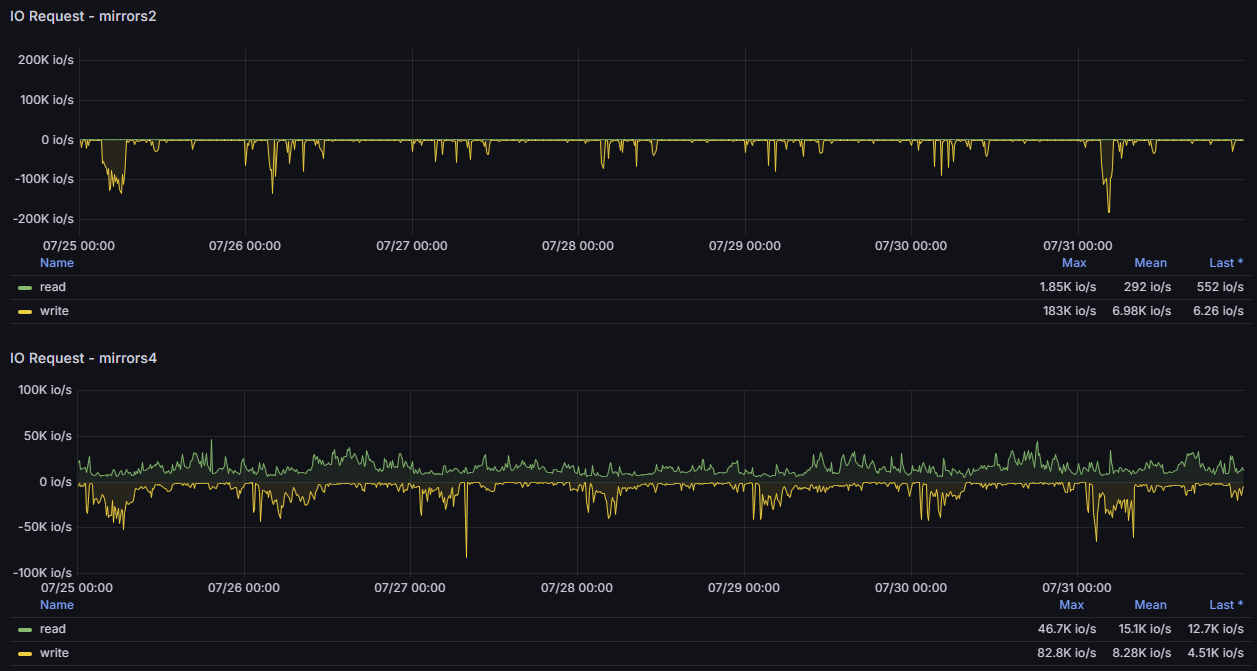
令 UC 震惊部出动的是,一个机械盘阵列竟然能跑出平均 15k、最高 50k 的 IOPS。 我们发现这个统计数字算上了 ARC hit,也就是只有一小部分 I/O 请求是真正落盘的,那就好解释了。
AppArmor
换上先进的 PVE kernel 之后,我们很快就发现同步任务全挂了()
排查发现 rsync 在调用 socketpair(2) 的时候冒出了 EPERM,这是我们从来没遇到过的情况。
实际上这些系统调用都被 AppArmor 拦下来了,最终查到是 Ubuntu 在 kernel 里加的私货 security/apparmor/af_unix.c 导致的。
由于 Proxmox VE 的 kernel 是从 Ubuntu fork 过来的,这个私货也就被夹带到我们服务器上了。
我们发现 PVE 也打包了自己的 AppArmor features 配置,就把它直接拉过来用:
dpkg-divert --package lxc-pve --rename --divert /usr/share/apparmor-features/features.stock --add /usr/share/apparmor-features/features
wget -O /usr/share/apparmor-features/features https://github.com/proxmox/lxc/raw/master/debian/features
文件级去重
我们注意到个别仓库有大量的重复的、内容相同的目录,怀疑可能是同步方法(HTTP)的限制导致目录的符号链接变成了完整内容的拷贝。

我们想到了 ZFS 的 deduplication,于是在 ZeroTier 仓库上做了一个初步的测试:
zfs create -o dedup=on pool0/repo/zerotier
# 导入数据
# zdb -DDD pool0
dedup = 4.93, compress = 1.23, copies = 1.00, dedup * compress / copies = 6.04
结果十分可观,但考虑到 ZFS dedup 一向来糟糕的名声,我们还是不太想在镜像站上启用。 所以我们重新找了个更灵车的方案:
# post-sync.sh
# Do file-level deduplication for select repos
case "$NAME" in
docker-ce|influxdata|nginx|openresty|proxmox|salt|tailscale|zerotier)
jdupes -L -Q -r -q "$DIR" ;;
esac
这个用户态的文件去重工具十分好用,效果堪比 ZFS,而且没有性能损失。 我们对几个明显有重复内容的仓库跑了一下 jdupes,结果如下:
| Name | Orig | Dedup | Diff | Ratio |
|---|---|---|---|---|
| proxmox | 395.4G | 162.6G | 232.9G | 2.43x |
| docker-ce | 539.6G | 318.2G | 221.4G | 1.70x |
| influxdata | 248.4G | 54.8G | 193.6G | 4.54x |
| salt | 139.0G | 87.2G | 51.9G | 1.59x |
| nginx | 94.9G | 59.7G | 35.2G | 1.59x |
| zerotier | 29.8G | 6.1G | 23.7G | 4.88x |
| mysql-repo | 647.8G | 632.5G | 15.2G | 1.02x |
| openresty | 65.1G | 53.4G | 11.7G | 1.22x |
| tailscale | 17.9G | 9.0G | 9.0G | 2.00x |
参考上述表格,我们排除了 mysql-repo,因为它的去重比例太低,不值得花费跑一遍去重产生的 I/O 负载。
总结
ZFS 解决了我们镜像站上的一大堆问题,并且有了此次调参经验,我们现在宣布 ZFS 天下第一(不是)
有了 ZFS 之后:
- 我们不再担心分区问题,ZFS 可以灵活分配。
- 我们的机械盘比别人的固态盘跑得还快,这非常 excited!
- 我们成为了第一个不再羡慕 TUNA 的全闪服务器的镜像站!
- 零成本获得额外容量,由 ZFS 透明压缩和去重联合赞助!
思考
虽然我们的 ZFS 配置看起来非常高效,但我们也知道 ZFS 在长期运行中可能会因为碎片化而导致性能下降的问题。 我们会持续关注我们的服务器,监控长期的性能变化。
-
指本文所述的重建工程之前,即 2024 年 6 月中旬。 ↩